


As a cloud database user myself, I am always looking for ways to speed up my query runtime and reduce costs. Cloud databases are powerful, but if you don’t pay attention to how and when you are running your queries, costs can quickly add up. In this article, I’ll share the top SQL tips to optimize your queries and ensure you have the lowest runtimes and the lowest costs.
SQL query optimization best practices:
- Use indexes effectively
- Avoid SELECT * and retrieve only necessary columns
- Optimize JOIN operations
- Minimize the use of subqueries
- Avoid redundant or unnecessary data retrieval
- Utilize stored procedures
- Consider partitioning and sharding
- Normalize database tables
- Monitor query performance
- Use UNION ALL instead of UNION
- Optimize subquery performance
- Leverage cloud database-specific features
I like to think of indexes as primary keys and mapping tables in SQL. In wide data tables, you often see identification codes or integers that map to another data table. This is an effective way of storing data because it allows you to easily query the wide table and join values back to another table—essentially, this provides more details on a data row. You also see indexes in the form of primary keys that allow you to select a unique row.
These two indexing methods help you locate data in tables more quickly. Because indexes store data in one or more columns, you can easily find one value or even a range of values. For example, if using a WHERE clause in a query, an index prevents you from having to scan the entire table. Instead, you can simply look for a match condition. This ends up saving you a lot of time if you’re performing these types of queries often.
Keep in mind that cloud data warehouses like Redshift and Snowflake are columnar and don’t have indexes like relational databases. They automatically partition data based on the distribution of data during the load time. Here, I recommend loading the data in a sorted order that you query often. You can also override the partition, causing the database to recluster and distribute the data accordingly.
There are three main types of indexes:
Clustered indexes
Clustered indexes physically order the columns based on their actual value.
You only want to use clustered indexes when your column values are in sequential or sorted order and there are no repeat values. This is because the index is ordering them based on the actual value within the column itself. Once this index is created, it will then point to the row that contains the data—not the data itself. Primary keys are a form of clustered indexes.
Non-clustered indexes
Non-clustered indexes create two separate columns—one for the index and the other that points to the value. This type of index is typically used for mapping tables or even any type of glossary. You have certain column values that point to a specific location. Unlike clustered indexes, the index points directly to the data.
If you’re choosing between these two indexes, clustered indexes are the way to go. They are faster and require less memory to run since they don’t exist in two separate locations. This practice optimizes your cloud data warehouse performance.
Full-text indexes
There are also full-text indexes, which are more rare, but allow you to search through columns with a lot of text, like those that hold article or email content. This type of index stores the position of the terms found in the indexed field, making it much easier to find.
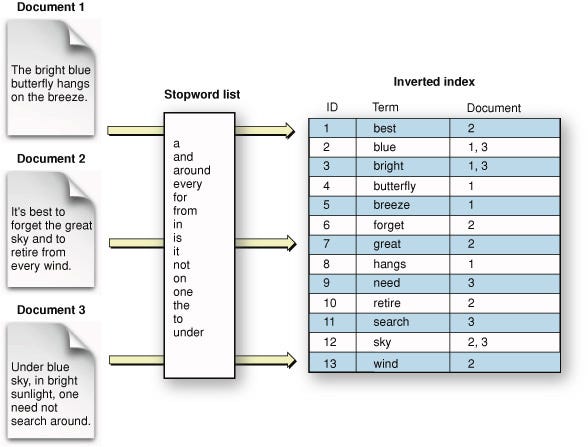
Believe it or not, when exploring different datasets in your data warehouse, you don’t want to use a SELECT *. These types of queries are actually quite inefficient because you are choosing to view all fields in a dataset rather than just the ones you are interested in.
When writing your queries within a data model, be sure to leave out columns that will never be used by data analysts or business users. If you are writing a query for reporting purposes, only include the columns the business users want to look at. When working to prevent confusion and optimize run-time, less is always better!
Selecting only the specific fields you want or need to view will keep your models and reports clean and easy to navigate. Here’s an example of what that could look like:
SELECT * FROM customers.customer_profiles →
SELECT customer_name, customer_email, customer_phone FROM customers.customer_profilesJoins can make or break complex queries. It’s imperative that you know the difference between an inner join, outer join, left join, and right join. Using the wrong join can create duplicates in your dataset and slow it down massively.
Outer join
I recommend only using an outer join if you have a very specific use case that can’t be solved otherwise. Outer joins returned matched and unmatched rows from both of the tables that you are joining. It essentially returns everything from both datasets in one dataset, which in my opinion basically defeats the purpose of a join. Outer joins produce a lot of duplicates and return pieces of data you probably don’t need, making it inefficient.
Inner join
Inner joins return only the matching records from the two tables that you are joining. This is almost always preferred over an outer join.
Left and right joins
Left and right joins return all records from one table and only matching records from the table being joined. For left joins, the resulting query would contain all values in the first table and only the matching tables in the second. For right joins, it is the opposite—the resulting query would contain all values from the second table and only the matching records from the first table.
I recommend always choosing a left join over a right. In order to make this work, simply change the order you are joining your tables. Left joins are a lot easier to read and understand as compared to right joins—making this type of join better for data governance, reliability, and data quality.
Lastly, with joins, make sure you are joining the two tables on a common field. If you are selecting a field that doesn’t exist to join the tables together, you may get an extremely long-running query that will end up wasting your time and money. I recommend verifying that joins are utlilizing primary and foreign keys that exist between two tables.
Here’s an example of a left join:
SELECT
Profile.customer_name,
Profile.customer_email,
Address.home_state
FROM customers.customer_profiles profile
LEFT JOIN customers.customer_addresses address
ON profile.customer_id = addresses.customer_idAlso, don’t be afraid to join on more than one column if need be. Sometimes this can help reduce resulting duplicates and speed up run-time in the case of multiple records with the same joining field.
Here’s an example with an inner join:
SELECT
Customer_orders.customer_id,
Order_details.order_id,
Order_details.order_date
FROM customers.customer_orders customer_orders
INNER JOIN orders.order_details order_details
ON customer_orders.customer_id = order_details.customer_id
AND customer_orders.customer_order_id = order_details.order_idSubqueries are very hard for anyone to read and understand. Instead of using subqueries, especially in complex models or reporting, opt for CTEs instead. CTE stands for common table expression and separates your code into a few smaller queries rather than one big query.
CTEs make it easy for anyone reading through your code to understand it. As an added bonus, theyalso simplify the debugging process. Rather than having to pull each subquery out into its own query and debug at each stage, you can simply select from each CTE and validate as you go. Here’s an example:
SELECT MAX(customer_signup) AS most_recent_signup FROM (SELECT customer_name, customer_phone, customer_signup FROM customer_details WHERE YEAR(customer_signup)=2023)
→
WITH
2023_signups AS (
SELECT
customer_name,
customer_phone,
customer_signup
FROM customer_details
WHERE YEAR(customer_signup)=2023
),
Most_recent_signup AS (
SELECT
MAX(customer_signup) AS most_recent_signup
FROM 2023_signups
)
SELECT most_recent_signup FROM Most_recent_signupAs you can see, the CTE is a little bit longer, but it’s much easier to understand. Now, any reviewer can analyze each smaller piece of the query and easily relate each component back to one another.
When exploring datasets, developing reports or models, and validating data, it is important to only retrieve the data that you need. This way you aren’t spending money or utilizing compute resources on data that you don’t need. As we mentioned before, it’s important to only select the necessary columns rather than SELECT *. However, it is also important to limit the number of rows you are returning, not just columns. With relational databases like MySQL and Postgres, they slow down when the number of rows increase.
You can use LIMIT to reduce the number of rows returned. You will typically see SQL editors like dbeaver set a feature to limit the data return to 100 or 200. This built-in feature prevents you from unknowingly returning thousands of rows of data when you just want to look at a few.
These functions are particularly useful for validation queries or looking at the resulting output of a transformation you’ve been working on. They are good for experimentation and learning more about how your code operates. However, these types of functions are not good to use in automated data models where you will want to return all of the data.
To use LIMIT:
SELECT customer_name FROM customer_details ORDER BY customer_signup DESC LIMIT 100;This will only return 100 rows, even if you have more than 100 customers.
You can also add an OFFSET clause to your LIMIT functions if you don’t want to return the first 100 rows, but want to skip some first. If you wanted to skip the first 20 rows and select the 100 customers after that, you would write:
SELECT customer_name FROM customer_details ORDER BY customer_signup DESC LIMIT 100 OFFSET 20;While these queries help to limit data, cloud data platforms also help to reduce impact of redundant queries by leveraging caches. You can also take advantage of temporary tables in cloud platforms to store repeat queries—just remember to delete them when you are finished using them!
Stored procedures are database objects that contain lines of SQL code. They can be reused and automated in order to speed up development time and simplify logic. You can think of them as “functions”, like those that exist in Python and Javascript, that can be saved and applied in your code environment.
Stored procedures improve performance in your cloud database because they compile and cache code, allowing increased speed with frequently used queries. They also simplify a lot of processes for developers by existing as a reusable piece of code. Developers don’t have to worry about writing the same piece of code over and over again. Instead, they can utilize SQL functions that already exist in the form of a stored procedure.
You can create a stored procedure like so:
CREATE PROCEDURE find_most_recent_customer
AS BEGIN
SELECT
MAX(customer_signup) AS most_recent_signup
FROM 2023_signups
END Then, you can run this procedure using the following command:
EXEC find_most_recent_customer; You can also pass parameters into stored procedures by specifying the column name and datatype.
CREATE PROCEDURE find_most_recent_customer
@store_id INT AS BEGIN
SELECT
MAX(customer_signup) AS most_recent_signup
FROM 2023_signups
WHERE store_id= @store_id
END Simply include the column_name that is going to be the parameter using an @ sign and the data type you want it to be passed through. Then, to execute it, you again specify the parameter and its value.
EXEC find_most_recent_customer @store_id=1188; This allows you to really customize your stored procedure for your specific use case while still reusing code that’s already been written and automated.
Partitioning and sharding are two techniques you can use to spread the distribution of data in the cloud.
With partitioning, you divide one large table into multiple smaller tables, each with its own partition key. Partition keys are typically based on the timestamps of when rows were created or even on the integer values they contain. When you execute a query on this table, the server will automatically route you to the partitioned table appropriate for your query. This improves performance because, rather than searching the entire table, it is only searching a small part of it.
Sharding is quite similar except, instead of splitting one big table into smaller tables, it’s splitting one big database into smaller databases. Each of these databases is on a different server. Instead of a partition key, there is a sharding key that redirects queries to be run on the appropriate database. Sharding is known to increase processing speeds because the load is split across different servers—both working at the same time. It also makes databases more available and reliable due to the fact that they are completely independent of one another. If one database goes down, it doesn’t affect the other ones.
Keep in mind that modern cloud data platforms do this automatically when you define the partition key and distribution type on load. AWS also offers a relational database product called Aurora which automates partitioning and sharding.
The premise of normalization is to make sure the values in your database tables are easy to locate and query. Normalization at the layer closest to your raw data is important so that you can easily query the values downstream. We cover this idea more in our article on data modeling.
First Normal Form (1NF)
I often run into issues with JSON objects in my raw data. Parsing these JSON objects is a type of normalization that ensures no nested objects exist in your data. This is actually called First Normal Form (1NF). With this form of normalization, values must exist as atomic values (values that can’t be broken down into smaller values) and each row must have a primary key.
Second Normal Form (2NF)
Second Normal Form (2NF) is a different type of normalization that requires fields with multiple values to be broken into their own rows. This allows you to easily access each value stored in a field because it now exists dependently on the primary key but in a different row.
Third Normal Form (3NF)
Third Normal Form (3NF) is another type of normalization. Second normal form is actually a prerequisite to this type of normalization. So, if using this form, make sure you follow the steps for 2NF first. Then, you want to look at your table and see if any column values are dependent on one another. For example, if you have a customers table with the customer name, phone number, state, and zip code, zip code is dependent on state. You can further break these values down into another table. Zipcode and state would exist in their own table while customer name, phone number, and state exist in another.
If you remember the transitive property from high school geometry class, this is essentially what that does. It says “Hey, if this column depends on that column for its value, then that value can be moved to a separate table”.
While there is also fourth normal form and fifth normal form, these normalization techniques are less popular and not needed for the scope of this article.
Monitoring SQL query performance is key when trying to optimize your SQL queries. If you don’t ever look at the run-time of your queries, you will never know which ones are taking the longest! This is key to determining which ones need to be optimized and will have the most cost savings for you in your cloud database.
One tool to optimize performance is query profiling. This allows you to pinpoint the source of performance issues by looking at statistics such as runtime and rows returned. Query profiling also includes query execution plans which give you insight into what code is running in what order before it runs. To optimize query performance you can also look at database logs, the server itself, and any external applications connected to your cloud database.
UNION is an operator used to join the outputs of two SQL queries. It comes in handy when you need to combine two datasets that have the same column names. However, it is important that you understand the difference between the two UNION operators- UNION and UNION ALL.
UNION joins all of the rows from Table A with all of the rows from Table B. No deduplication occurs. However, UNION ALL joins all of the rows from Table A with all of the rows from Table B and then deduplicates rows that contain the same values. If you don’t care about duplicates, UNION is going to save you a lot of processing time compared to UNION ALL. I typically always opt for UNION because, even if there are duplicates, I would want to know about them and take the time to understand why that is happening.
While I don’t recommend using subqueries when trying to optimize performance, sometimes they are fast and handy when doing a quick and dirty analysis. If you need to do something like check whether values exist in another table or sql subquery, it’s best to use an EXISTS statement over an IN statement.
EXISTS returns a boolean value, quickly comparing values and moving on to the next when a value is not present. IN compares every value since it returns the value itself, slowing down the processing time of the query. However, IN is more efficient to use than something like an OR statement which scans a table for multiple different conditions.
Instead of this…
SELECT
Customer_id
FROM customer_details
WHERE state_id=3 OR state_id=11 OR state_id=34 Do this…
SELECT
Customer_id
FROM customer_details
WHERE state_id IN (3, 11, 34)In this case, it is much more efficient to use the IN clause rather than the OR. However, in the following example, it makes more sense to use an EXISTS rather than an OR because two different tables are being compared.
Instead of this…
SELECT customer_id FROM customer_details WHERE order_id IN (SELECT order_id FROM order_details WHERE order_type_id=3)Do this…
SELECT customer_id FROM customer_details WHERE EXISTS (SELECT * FROM order_details WHERE customer_details.customer_id = order_details.customer_id)This will return all of the rows that prove true rather than scanning and comparing every value like with an IN clause.
One of the many benefits of using a cloud database is the database-specific features that come with it. Snowflake, for example, has a ton of SQL functions specific to Snowflake that make creating transformations easier. These include functions for parsing JSON values and working with different data type. Check with your cloud provider to see if they have specific optimizations they recommend.
Conclusion: SQL query optimization
Cloud databases are a powerful tool for taking your data environment to the next level. They allow you a lot of flexibility, but that doesn’t mean you need to sacrifice performance. You can use a lot of the features offered by these databases in combination with smarter SQL in order to keep costs down and performance high.
A lot of these tricks are about knowing which features to utilize in which situations. But it's just as important to know what SQL functions to avoid. Now you have the tools you need to look at how you are using SQL in your cloud database and improve it for better data reliability, data quality, and data accessibility.


