



The most successful organizations today know they need to use business analytics to make decisions and drive outcomes. Often, however, these decisions must be driven by insights that can remain hidden in data. That’s where data mining comes into play. Data mining is a powerful tool to help extract meaningful insights from even the largest, most complex data sets. Whether you’re a data analyst or scientist seeking out correlations between customer behaviors, marketing campaigns, and weather, or searching for trends in stock pricing, data mining can be the pathway to uncovering valuable insights.
With so much information floating around, it’s no wonder that more and more people are turning to this technology; but where do you start? In this post, we’ll provide an introduction to data mining: what it is, the data mining process, techniques used in data mining, and industry applications of how you can start using it.
What is data mining?
Data mining is a process of extracting insights from large datasets by analyzing it to uncover hidden patterns, anomalies and outliers, correlations, and trends. It works by breaking data down into smaller chunks and then looking for relationships between the different data. The process can involve sorting through complex algorithms to find significant correlations or patterns that may have gone undetected. Often, machine learning or AI is leveraged, alongside various statistical methodologies, to identify these correlations.
In today's world, data mining has become an important part of any data-driven organization. It can help them to make better decisions that lead to increased customer satisfaction, improved processes, mitigate risk, and deliver more revenue.
4 stages to follow in your data mining process
1. Data cleaning and preprocessing
Data cleaning and preprocessing is an essential step of the data mining process as it makes the data ready for analysis. Data cleaning process includes deleting any unnecessary features or attributes, identifying and correcting outliers, filling in missing values, and converting categorical variables to numerical ones. This involves removing or correcting erroneous, incomplete, or inconsistent data, as well as formatting the data into a usable format for analysis. Preprocessing also includes normalizing the data, reducing its dimensionality, and performing feature selection to identify important features.
Many companies include these steps as part of their broader data governance initiatives. After cleaning and preprocessing is complete, the data is ready for exploration and visualization.
2. Data modeling and evaluation
Data modeling and evaluation is the process of training machine learning models with the data and then evaluating their performance. This involves selecting an appropriate algorithm for the task, tuning its hyperparameters to optimize its performance, and using measures such as accuracy or precision to evaluate its results. After a model is trained and evaluated, it can be deployed for real-world applications. In addition, data mining can also be used to detect anomalies or outliers in the data. This is especially useful for fraud detection and cybersecurity applications. After identifying any anomalies or outliers, analysts can then investigate further to gain more insight into the problem.
3. Data exploration and visualization
Data exploration and visualization is the process of exploring, analyzing, and visualizing data to gain insights and identify patterns. This involves summarizing the data using descriptive statistics, such as measuring its central tendency, dispersion, and correlation between features; plotting distributions of data points; and performing clustering or classification algorithms to group similar data points together. Through these methods, data professionals, including data analysts, data scientists, and analytics and data engineers, can gain insight into the underlying structure of the data and identify relationships between features.
Data visualization tools, such as heatmaps, histograms, bar charts, and scatter plots, can also be used to easily communicate and see how different datasets relate, correlate, and diverge. Additionally, dimensionality reduction techniques such as principal component analysis (PCA) can help reduce the complexity of datasets by representing them in fewer dimensions. After exploring and visualizing the data, analysts can decide which machine learning algorithms would be most suitable for their project.
4. Deployment and maintenance
In the final stage of data mining, the trained models are deployed in a production environment. This requires configuring the model for real-time execution and setting up any necessary monitoring mechanisms to ensure its performance. Additionally, any changes made to the model or dataset may require re-training the model and redeploying it to production. Finally, maintenance is also necessary to ensure the performance of the model and keep it up-to-date with any changes to the data or environment. By keeping track of these factors, businesses can ensure that their data mining models remain accurate and can give reliable results in production.
Techniques used in data mining
Association rule mining
Association rule mining is a popular technique that involves the discovery of interesting relationships in large datasets. This process enables data miners to identify patterns and associations among variables, such as items commonly purchased together or frequently occurring sequences in customer transactions.
Association rule mining is based on the concept of strong rules which are defined as having high confidence, lift, and support values. The mined rules can be used to make predictions and suggest further actions.
For example, a rule that states “If customers purchase product A, then they are likely to purchase product B” can be used to suggest product B as a related item for customers who are viewing or purchasing product A. The end result of an association rule mining exercise is a set of rules that can be used to make decisions, suggest further actions, and/or improve the understanding of customer behavior.
Clustering
Clustering is a data mining technique that does not require labeled data. Instead, clustering uses similarity measures between different data when grouping them. Clustering is often used for exploratory data analysis to find hidden patterns or groupings in data. It can also be used for segmentation, which is the process of dividing a dataset into groups based on similarities.
For example, clustering can group customers together based on their purchasing habits. Different clustering algorithms have different approaches for determining the similarity of items, such as distance-based, connectivity-based, and density-based approaches. Commonly used clustering algorithms include k-means and hierarchical clustering. The results of clustering can be used in many different applications, such as market segmentation and customer segmentation. Clustering is also widely used beyond structured data, such as in document analysis, image recognition, and text mining.
Classification
Classification is used to assign items into predefined classes based on the values of their attributes. Classification involves the use of labeled training data, which the algorithm uses to build a model that can then be used to classify new items. By classifying items into predefined groups, the classification algorithm can help identify patterns and trends in the dataset that may not have been otherwise notified.
Additionally, classification can be used to make predictions about new items, such as predicting whether a customer is likely to make a purchase or not. The model is typically created using supervised learning and it consists of decision trees, rules, or mathematical equations.
Anomaly detection
Anomaly detection is a data mining technique used to identify items or events that do not conform to an expected pattern. By identifying items or events that do not conform to expected patterns, anomalies can be used to detect fraud, diagnose mechanical failures in industrial systems, and identify network intrusions. Additionally, anomaly detection can help improve process efficiency.
Industry applications of data mining
Finance and Banking
Data mining is used in the finance and banking industry to identify patterns that may indicate fraud or money laundering. By detecting these suspicious activities, financial institutions can reduce losses and protect customers from fraudulent activity. Additionally, banks can use data mining to better understand customer behavior and create targeted marketing campaigns that promote their products and services. Data mining can also be used to develop credit scoring models that can be used to assess customer risk. These models help financial institutions make decisions about loan approvals, interest rates, and other factors.
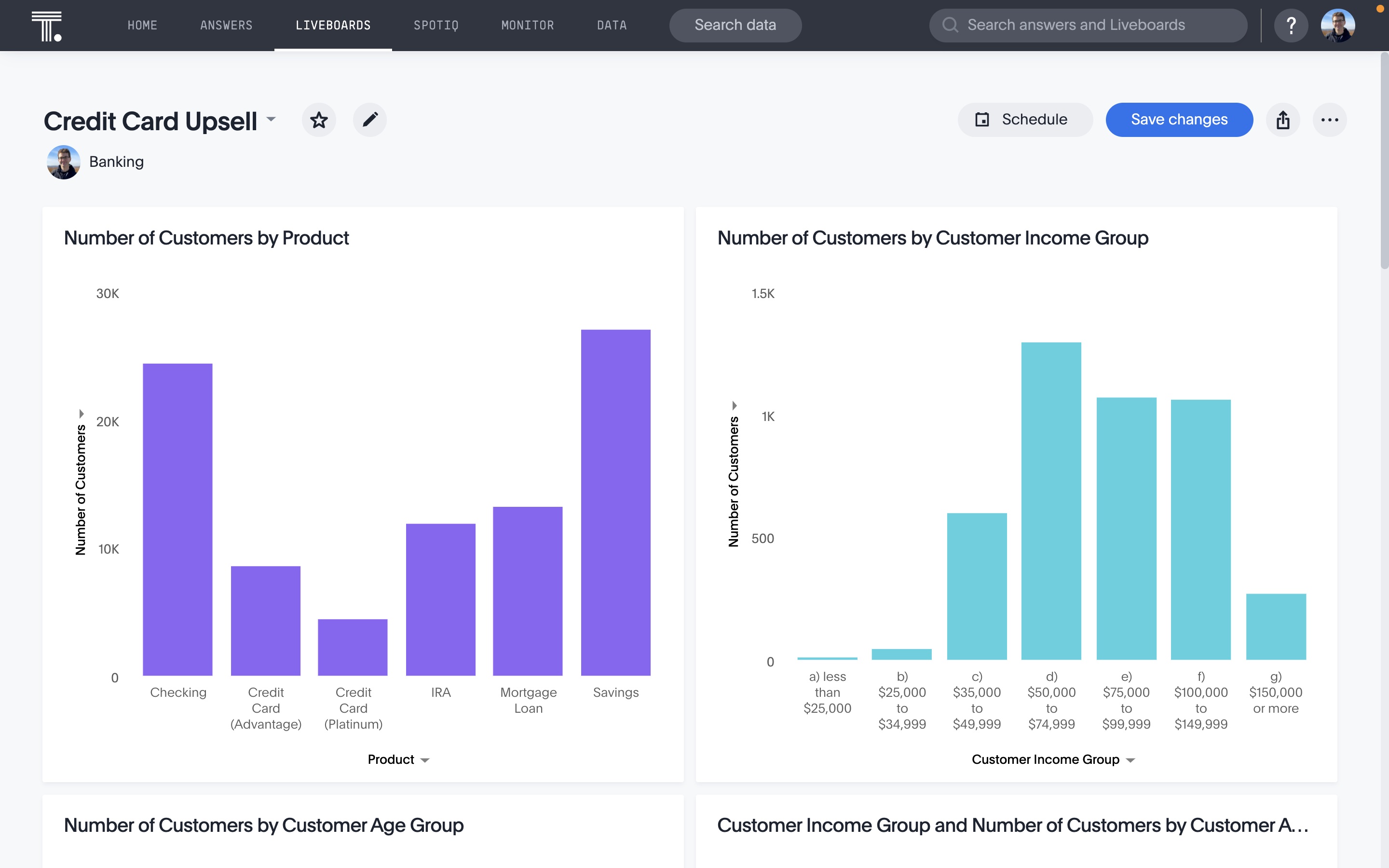
The use of data mining in the finance and banking industry has become increasingly important as the industry becomes more complex and data-driven. It is a powerful tool for promoting trust between banks and their customers and ensuring the safety of customer funds.
Retail and E-commerce
In retail, understanding and delighting customers is essential for success. Data mining can be used to help retailers get a far more holistic understanding of their customers’ shopping habits. By analyzing large data sets, retailers can gain insights into what products customers prefer, which items they tend to buy together, and which promotions are most effective. This information can help businesses create more targeted marketing strategies and optimize their inventory management. Additionally, data mining can be used to identify patterns in customers' purchasing decisions that may indicate fraud or misuse of credit cards. When these insights are exposed to business users, ideally by empowering them to find insights on their own self service analytics, retailers can take steps to protect themselves from financial losses due to fraudulent activity.
Healthcare
The explosion of data has created huge opportunities for healthcare organizations to improve patient outcomes, operate more efficiently, and improve their bottom lines. By analyzing large amounts of patient data, healthcare providers can identify trends that may indicate health risks or the need for further medical evaluation. This information can help doctors and other medical professionals make better decisions about care and treatment and provide more personalized services to patients. Additionally, data mining can be used to identify potential drug interactions, detect fraudulent activity in medical claims processing, and improve the accuracy of diagnosis.
By using data mining to glean insights from patient data, healthcare providers can improve overall care quality and reduce costs.
Manufacturing
Companies can use data mining to analyze production data, power supply chain analytics, and identify trends and patterns that may indicate potential problems or areas of inefficiency. With this information, manufacturers can take steps to improve production processes and increase efficiency. Additionally, data mining can be used to monitor product quality, identify opportunities for automation and process improvement, and find ways to reduce costs.
By using data mining to better understand production data, manufacturers can increase their productivity and ultimately improve their bottom line.
Telecom
Data mining is also used in the telecom industry to better understand customer behavior and preferences. By analyzing call records, companies can identify trends that may indicate calling patterns or potentially fraudulent activity. Additionally, data mining can be used to develop personalized marketing campaigns that target customers with specific products and services. Telecom companies are also using data mining to improve network utilization and customer service, by analyzing customer data and identifying areas where service can be improved.
With the help of data mining, telecom companies can better understand their customers and provide more tailored services that meet their needs.
Future of data mining
Data mining is an increasingly important tool for businesses and organizations of all kinds. As artificial intelligence and machine learning become more advanced, data mining will become even more powerful. Companies will be able to analyze larger and more complex datasets, uncovering insights they may have previously been unable to detect.
That said, as ethical considerations and regulations around data usage become more stringent, organizations will need to take greater care when using data mining. As companies become increasingly aware of the potential benefits and risks associated with data usage, they will be better equipped to responsibly harness its power. Ultimately, data mining has the potential to provide businesses and organizations with invaluable insights that can help them make more informed decisions and stay ahead in an ever-changing and competitive global market.
Make better decisions with your data
Data mining is important because it is an important part of any analytics strategy. When done correctly, it’s an incredibly helpful tool that helps organizations make the most of their data. Doing so, however, requires exposing the models built through data mining, and more importantly, the insights these contain, to decision makers and business users. With ThoughtSpot, everyone can engage with data directly through a simple, familiar search experience. If you want to reap the most ROI from your data, sign up for a ThoughtSpot free trial today and see how easy it is to use AI analytics to visualize your cloud data.


