



This is the third blog in Cloud Thoughts, a series delving into the details of deploying ThoughtSpot in the Cloud. Read parts one and two for more.
Enterprises in every industry continue to march toward the cloud, chasing the flexibility and agility needed to thrive in today’s market. While they’re definitely finding these benefits, many are also shocked by the cost of running some applications in the cloud.
At ThoughtSpot, we’re dedicated to lowering the cost of infrastructure required to deploy search and AI-driven analytics in the cloud. That’s why we are so excited to announce changes in the persistent storage layer that make use of object storage to help lower the cost of your ThoughtSpot AWS and GCP deployments by as much as 10%. Not only will these changes help you reduce costs; they’ll also improve your ability to scale the ThoughtSpot cluster without needing to make any changes to your cluster configuration.
New ThoughtSpot Deployment Model
What it is.
It’s a means to lower the cost of a ThoughtSpot AWS or GCP deployment by persisting a significant portion of user and application data in object storage (AWS S3 and GCP Google Cloud Storage).
What it’s not.
It’s not a way to run ThoughtSpot queries directly against data stored in your S3 or GCS bucket. User data must still be loaded into memory, with queries being executed on data stored in RAM on the VM instance. The S3 or GCS bucket is controlled by the ThoughtSpot application and serves as the persistence layer that helps retrieve data into memory on the instance (during data loads or if the VM restarts).
As laid out in a prior blog post, ThoughtSpot is deployed in the cloud using a combination of cloud compute (VM) instances and an underlying persistent storage layer that form a cluster of nodes. These nodes power ThoughtSpot's massively parallel in-memory calculation engine to execute thousands of queries and uncover interesting insights on billions of rows of data.
The persistent storage layer is responsible for retrieving all user data and user-generated analytics content into memory (RAM) on the cluster nodes (VM instances in cloud).
Prior to 5.3, ThoughtSpot’s persistent storage implementation on AWS used Amazon Elastic Block Store (EBS) as the only underlying storage infrastructure, with a Hadoop Distributed File System (HDFS) layer to enforce redundancy across nodes in a cluster. Similarly, the GCP deployment was backed by SSD Persistent Disk before the release of 6.0.
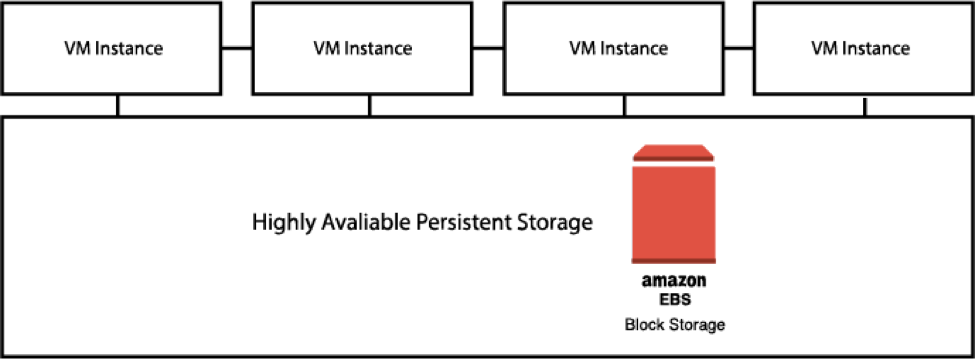
In this deployment model, persistent storage capacity (AWS EBS or GCP SSD Persistent Disk) needs to be provisioned per VM. The size of the persistent storage volumes is based on the amount of user data that can be loaded on to each VM instance.
The table below shows the AWS EBS and GCP SSD Persistent disk volume size that must be provisioned per VM for each supported VM instance type on AWS and GCP (in addition to the boot volume).
|
AWS VM instance type |
User data capacity per VM |
EBS data volumes per VM |
|
r4.4xlarge, r5.4xlarge |
20GB |
2x400GB |
|
r4.8xlarge, r5.8xlarge |
100GB |
2x400GB |
|
r4.16xlarge, r5.16xlarge |
250GB |
2x1TB |
|
m5.24xlarge |
192GB |
2x1TB |
|
r5.24xlarge |
384GB |
2x1.5TB |
|
GCP VM Instance type |
CPU/RAM |
Per VM user data capacity |
Zonal Persistent SSD Disk volume per VM |
|
n1-highmem-16 |
16/122 |
20 GB |
2X 400 GB |
|
n1-highmem-32 |
32/208 |
100 GB |
2X 400 GB |
|
n1-standard-96 |
96/330 |
180 GB |
2X 1 TB |
|
n1-highmem-64 |
64/416 |
208 GB |
2x 1 TB |
Object storage is cheaper than block storage in all the major cloud provider environments like AWS, Azure and GCP. Utilizing object stores can help lower the infrastructure cost for ThoughtSpot AWS deployments by up to 10%.
Beginning with the 5.3 release for AWS and the 6.0 release in GCP, we now support a deployment model that uses AWS S3 and Google Cloud Storage (GCS) for a major portion of persistent storage.
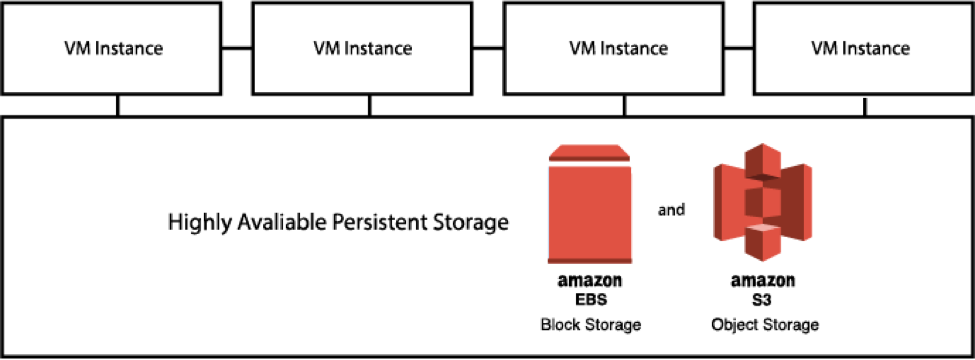
In this deployment model, a major part of the user data and some of the application data is persisted in AWS S3 or Google Cloud Storage, while a reduced (fixed) footprint of AWS EBS or GCP SSD Persistent Disk is used for other application data. Using S3 or GCS for the majority of persistent data reduces the total infrastructure cost of deploying ThoughtSpot. The size of persistent data goes down significantly in this model.
Here’s the deployment footprint with this model.
|
AWS VM instance type |
User data capacity per VM |
EBS data volumes |
S3 bucket size |
|
r4.4xlarge, r5.4xlarge |
20GB |
1x500GB |
Approximately equal to the size of user CSV data (plus a small amount of indexing and other application data) |
|
r4.8xlarge, r5.8xlarge |
100GB |
1x500GB |
|
|
r4.16xlarge, r5.16xlarge |
250GB |
1x500GB |
|
|
m5.24xlarge |
192GB |
2x1TB |
|
|
r5.24xlarge |
384GB |
2x1.5TB |
|
GCP VM Instance type |
Per VM user data capacity |
SSD persistent disk |
GCS bucket size |
|
n1-highmem-16 |
20 GB |
1x500GB |
Approximately equal to the size of user CSV data (plus a small amount of indexing and other application data) |
|
n1-highmem-32 |
100 GB |
1x500GB |
|
|
n1-standard-96 |
180 GB |
1x500GB |
|
|
n1-highmem-64 |
208 GB |
1x500GB |
|
|
n1-highmem-96 |
312 GB |
1x500GB |
Using S3 or GCS also achieves compute storage separation, due to the fact that persisted data can now scale independently of compute. In order to learn more about provisioning S3 or GCS as persistent storage, please visit the Cloud section of our documentation.
As we continue to find ways to help you get more value out of your data in the cloud, this is just the beginning. We are working on supporting the object-store-based deployment model on the Azure platform as well, so stay tuned for that announcement as well as several other exciting developments.



