



インターネット接続のない生活を送っている人でなければ、ChatGPTという言葉をきっと耳にしたことがあると思います。現在、ChatGPTプラットフォームが実際にどのように使われているのか、ChatGPTが社会のあり方をどう変えようとしているのか、といった話題が注目を集めています。これほど面白いものが登場すると、どうしてもその仕組みを知りたくなるというものです。しかし、10年以上機械学習を研究し、この分野に積極的に関与してきた私でも、初めてChatGPT関連の研究論文を読んだときに「これは手ごわい」と感じました。理解しようとしても、論文はどれも私の知らない概念を示しており、その概念について別の論文を読もうとすると、また理解できない概念が出てくるのです。このモグラたたきのような格闘の末、ChatGPTや類似のテクノロジーの仕組みを初歩的な原則から説明した論文を理解できるようになりました。
この記事は、話題沸騰中のChatGPTが誕生するまでの技術革新のタイムラインを簡単に説明しようという試みです。基本的なコンピューターサイエンスや確率がわかる人なら、十分に読み進められると思います。複雑な数学や技術的な議論に入ることなく、これらがどうつながっているのかある程度理解できるでしょう。
実は、このモデルが何をどうやっているのか真に理解している人は誰もいないのです。それは、自分がどうやって自転車に乗ったり歩いたりできるのか誰も知らないのと同じです。でも、それは何が起こっているのかを把握していないわけではありませんし、私たちがここまで到達したことは確かなのです。
この記事は、全体が4つのパートに分かれています。
コンピューターによる言語理解の簡単な歴史――言語学者とコンピューター科学者の初期の取り組みから話を始めます(本記事)。
トランスフォーマーアーキテクチャー:ChatGPTを支えるエンジン――RNNに始まりトランスフォーマーに至るSeq2Seqモデルを簡単に学びます 。
ChatGPT とその他の大規模言語モデルの新しい特性――驚くべき特性を持つ非常に大規模なトランスフォーマーモデルを使って言語モデルがどのように構築されているかを検証します。
AIの未来:ChatGPTの分野で注目すべきトレンド――アプリケーションと今後の研究、世界に対して意味することなどを扱います。
じっくり説明しなければならないことがたくさんあります。さっそく始めましょう。
ChatGPTとは? その仕組みは?
GPT(Generative Pre-trained Transformer)とは、直訳すると「生成的な事前学習を行なったトランスフォーマー」の意味になります。このGPTの頭に「チャット」が付くのは、GPTモデルにチャットのインターフェイスが付いているからです。OpenAI社が開発した「ChatGPT」は、人間のインプットに対して自然言語の応答を生成することができるAI言語モデルです。基本的には、高度なチャットボットです。
まずは、コンピューターによる言語理解とニューラルネットワークを使った機械学習という、縦糸と横糸のような2つのトピックを考えるところから始めましょう。どちらもとても奥が深く、技術的なトピックなのですが、ここでは多少正確さを犠牲にしてでも、コンピューターサイエンスの基本的な知識がある人なら理解できる程度に概念を簡略化したいと思います。
初期の自然言語処理(natural language processing:NLP)
コンピューター科学者と言語学者は、コンピュータープログラムになんとか言葉を理解させようと半世紀以上も努力してきました。言葉を理解させるには、まず単語の分類法を整備し、文章を品詞ツリーに分類し、タグ付けし、テンプレートとルールを使って意味を引き出す必要がある、と研究者の多くが信じていたのです。ところが、純粋に統計学的な視点から言語を解析する中で、早くも1950年代には、多くの情報が関係していることに気づきます。たとえば、文書中の1つの単語の重要度は、その単語がその文書で何回使われているかに正比例しており、逆に他の文書で現れる頻度とは反比例しています。1957年に発見されたこの考え方は、その派生形(TF-IDF)が今でも多くの検索エンジンで使われています。たとえば、「インドの言語」を検索する場合、マッチすべき最も重要な単語は「インドの」であり、「言語」は重要度が下がります。「インドの言語」という句に含まれる単語のうち、最も使用頻度が低い単語は「インドの」だからです。
言語モデル
あまり深く考えずに、次の文章の括弧をうめてください。「その犬は、耳をつんざくような大きな声で( )」。たいていの人なら「吠えた」と答え、「引っ掻いた」とは答えないでしょう。そこに入る可能性のある単語それぞれに確率をつけるとしたら、「吠えた」には相当に高い確率をつけ、それ以外は低い確率をつけるはずです。このように確率を計算するプロセスは「言語モデリング」と呼ばれ、ChatGPTは本質的に「言語モデル」です。ChatGPTは、1,750億個のプログラム可能な結合で構成された非常に大きなニューラルネットワークでもあるので、大規模言語モデル(Large Language Model:LLM)と呼ばれています。大規模といっても、どのくらい大きいのでしょうか。比較の目安ですが、人間の脳には10の15乗、約1,000兆のシナプス結合があると言われます。
言語モデルで面白いのは、1つの予測で終わりというわけではないことです。予測された単語をテキストに追加したら、また次の予測をして、さらに次の予測へと、ページがテキストでいっぱいになるまで続けることができます。スマートフォンのキーボードで予測入力をしているときに、これがリアルタイムで見られますね。多くのスマートフォンでは、次の単語がランクを付けて表示されます。表示されたままに単語を選択していくと、完全にスマートフォンの言語モデルによって作り出された奇妙な、だけど面白いテキストができあがります。もちろん、このモデルは洗練されたChatGPTの足元にも及びませんが。
最も単純な言語モデルの場合、長いテキストの中で並んで出てくる単語の組み合わせだけを考えて、その最初の単語が指定されたら、次の単語のヒストグラムを参照するという仕組みです。これが、いわば言語モデルの始まりです。たとえば、「フィッシング」という単語の後に最も続きそうな単語は、「メール」か「攻撃」でしょう。Googleのオートコンプリートを見ても、だいたい直観に合っていますね。
nグラム
少し進歩すると、ペアになる単語(バイグラム)だけを考えるのではなく、3つ(トリグラム)、4つ、5つと単語の連続が増えていきます。これらは合わせて「nグラム」と呼ばれました。連続が長くなるにつれて、可能性のある単語の数は指数関数的に大きくなります。そうなると、すべてのnグラムを言語モデルで保存して利用することはできません。ところが、幸いなことに、単語の連続が長くなるにつれて、その連続がテキスト内に出現する頻度は下がっていくので、統計的に有意な出現頻度以上になるようにしきい値を設定しておけば、データを構築することが可能になります。nグラムのコレクションができたら、次の単語を予測する最も簡単な方法は、現在のテキストにマッチする一番長い単語の連続を見つけ、次の単語の分布を使って確率を予測することです。これが、事実上、最も長期にわたり「最先端」と言われた言語モデルでした。
2000年代後半にGoogle翻訳に携わる友人に尋ねたことがあるのですが、Google翻訳は、要するに1つの言語のnグラムを別の言語のnグラムとマッチさせているだけのことで、文法などそれ以外のルールは考慮していないと聞かされて驚いたものです。
巨大なベクトルとして概念を表す
このnグラムモデルの最大の弱点は、単語の意味についての情報が一切ないことです。私としては、単語を巨大なベクトルとして表すという考え方が、統計的な自然言語処理の黎明期における最大の進歩だったと思います。ベクトル以前、類義語や関連語を検知するには、大きなツリー(オントロジー)の中に複数の単語を入れて、お互いにどの程度近いかを見るのが良いと考えられていました。実際、オントロジーに単語を登録することを仕事にする言語学者がたくさんいたほどです。しかし、この単語ツリーは、構造がやや恣意的になるという問題がありました。たとえば、あるオントロジーで「アルバート・アインシュタイン」は人々->科学者->物理学者->1800年代生まれという分類に出てくるのに、「相対性理論」は抽象概念->科学的概念->物理学->現代物理学という分類に出てくるといったことが起こり得ます。2つの単語は本来は密接に関連した概念のはずですが、この考え方では遠く離れてしまいます。
では、単語を整理する別の方法を考えてみましょう。とても大きいホワイトボードがあって、それぞれの単語は一定の大きさの円で表されており、この2次元平面の特定の点にそれぞれの円の中心があるとします。各単語はホワイトボード上で、お互いが関係する単語とは近くに、関係が薄い単語とは遠くに配置されます。<br><br>この方法であらゆる単語を配置するのは不可能に近い、とすぐにわかります。円が混みあってくると1つの円の隣に配置できる円の数は限られる(正確には6個)のに、1つの単語にはわずかに意味の異なる近しい単語がたくさんあるからです。では、これを2次元の平面ではなく3次元で考え、単語は円でなく球と考えたらどうなるでしょうか。こうすると関連する概念を詰め込む余裕が増えます。次元の数をもっと増やせば、指数関数的に増えます。256次元ぐらいまで行けば、単語の背後にある概念を表す素晴らしい方法になり、関連する概念は固まって近くに、無関係の概念は遠くに配置できるようになるでしょう。1つの単語が、その球の中心の座標を表す数百の実数で表されるということを意味します。これらの数字のベクトルが「単語埋め込み」と呼ばれるものです。
この考え方は非常に重要なので、これを別の方法でもう一度考えてみましょう。この後の例では、英語で最も頻繁に使われる単語1万語に限って考え、他の単語はすべて無視してください。ある人が、1,000個のトピックを持っているとします。そして、1つの単語がそれぞれのトピックに属しているかどうかを、0点から1点の尺度で評価するとします。たとえば、「マンゴー」は「フルーツ」というトピックに属しているので1.0点ですが、「黄色い物体」というトピックについては0.5点、「抽象的概念」というトピックについては0.0点になります。こうすると、1つの単語を1,000個の数字のベクトルで表すことができます。2つの単語が関係しているかどうかを知りたければ、それぞれのベクトルがどのくらい遠いか近いかを見るだけでわかります。もちろん、トピックがうまく選択されていないと、このスキームはうまく機能しません。とにかく、やるべきことは、1万語のすべての本質をうまく捉えられる1,000のトピックを用意し、それから1,000x10,000=10,000,000の重みづけを行うことです。このような作業は、これまで手作業で行われてきました。そして残念ながら、とても手間がかかる割には、結果もぱっとしません。
潜在意味解析
この問題をアルゴリズムを使って初めて解決しようとしたのが、1988年に発表された潜在意味解析(Latent Semantic Analysis:LSA)です。これは、文書中の単語のベクトルを合計すれば、その文書のトピックをうまく表せるのではないかという考え方です。逆に、その文書を表すベクトルに基づいて、その文書内の単語の分布を推測すると、正確な単語の分布は得られなくても、トピックとそのトピックと単語の関連性とがうまく決定できてさえいれば、かなり正確な単語分布に近いものが得られる可能性もあります。
さらに、ある文書について、元の単語分布とトピックのベクトルから再構築した単語分布との違いを測定することもできるはずです。この違いを「再構築エラー」と呼ぶことにしましょう。さて、非常に多数の文書があり、そのすべての文書にわたってエラーを合計するとします。ここでの重要なひらめきは、トピックの選択と単語との関連性との問題は、全体のエラーを削減しようとする数学的最適化の問題と考えることができるというものでした。
さらに、単語からトピック、トピックから単語を結ぶ関数を線形関数だと限定すると、単語に対してエラーを最小化できるような最適のトピックと最適のベクトルを見つけるプロセスは、主成分分析(Principle Component Analysis:PCA)と呼ばれるもう1つの数学の問題とまったく同じになります。幸いなことに、PCAには効率的に計算できる閉形式解があります。
このようにして計算されたベクトルは、単語どうしの概念の重複を特定するのに非常に役立ち、インターネット検索のような目的にも利用されました。ただ、このようにベクトルを計算するデメリットは、言語を任意の数学的最適化に単純化する代わりに、コヒーレンスの概念を無視してしまうという点です。ベクトルの数字の背後に隠された意味がわかる場合とわからない場合があるのです。これが、言語の高度な数学モデル化がどんどん説明不可能になっていく最初のきっかけでもありました。
単語のベクトル表現の重要性
そもそも単語埋め込みは、2つの単語の意味の類似性を測定するのに力を発揮するツールです。それが、埋め込みを計算するテクニックが向上するにつれ、驚くべき方法で単語の意味を使った演算ができることが明らかになりました。たとえば「王」という埋め込みを例にとると、「男」という埋め込みを引き算し、「女」という埋め込みを足し算すると、「女王」の埋め込みに非常に近いものが得られるのです。つまり、概念を数学的に操作できるということです。これは画期的なことです。それまでこの問題を解く唯一の方法は、ルールとロジックの適用による方法、いわば現実の複雑さをカプセルに押し込むような不安定な方法でした。
ところが、このような単語埋め込みを使えば、概念を1つの言語から別の言語にマッピングや翻訳したり、要約を作ったり、単語の意味を混ぜ合わせて別の単語を作ったりすることも可能です。たとえば、「ジャガー」+「動物」で「ジャガー」+「車」とは異なる概念を表せます。あるいは「悲しい」+「さびしい」を表す単語は何かと尋ねることもできます。実用的な例では、あるメールが重要なメールかスパムかを示唆する能力や、オンラインレビューを感情分析する能力、さらには意味検索を実行する能力も、モデルに与えることができるのです。
線形関数の先に
前述のLSAのアプローチでは、数学的・計算的に便利なように、単語からトピックに至る関数を故意に線形関数に限定していました。疑問として残るのは、もしこの線形関数の制限を解いたら、はたしてよりよい埋め込みの関数が見つかり、概念をもっとうまく表現できて、前述のようなさまざまな応用が可能になるのかという点です。
複層ニューラルネットワークは、任意に複雑な関数を表すために非常に有望な関数でしたが、なにしろ学習させるのが難しく、一般的に敬遠されていました。それにもかかわらず、少数の研究グループは複層ニューラルネットワークの力を強く信じ、なんとか役立つものにしようと各種の手法を数十年にわたって試し続けてきました。そして数々の試行錯誤を重ね、Geoff HintonのグループとYeshua Bengioのグループが、ニューラルネットワークが埋め込みとして表現された単語と概念を非常にうまく学習できることを実証したのです。その研究成果は、Yann LeCunによる畳み込みニューラルネットワーク(Convolution Neural Networks:CNN)の研究と共に、現在のようなニューラルネットワークが機械学習における最も強力なツールとして復活する重要な契機となったと考えられています。
AlexNetおよびGPU
2012年も、ニューラルネットワークの復活に関わる重要な年となりました。専門家の多くが評価するのがAlexNetです。GPUを使って大規模CNNにコンピュータービジョンタスクを学習させるAlexNetは、実用化されていたどんなモデルよりも大幅に優れたアウトプットをたたき出しました。GPUの利用はすでに注目されていたのですが、AlexNetの大成功が契機となって、研究者たちはこぞってより大きなニューラルネットワークを、より大きなトレーニングセットで計算を繰り返して学習させました。このとき研究者が得た重要な認識は、より多くのデータと計算をニューラルネットワークに与えるほど、より良い結果が得られるということです。これは他の機械学習手法ではほとんど見られないことでした。他のアプローチの多くはしばらくすると飽和状態に陥るのですが、ニューラルネットワークだけは進化し続けたのです。このアプローチから最も大きなメリットを得た2つの分野が、コンピュータービジョンとNLPです。ここからイノベーションは一気に加速し、現在もその勢いは止まりません。
単語にコンテキストを与える
単語と埋め込みを対応させようとするときに生じる問題の1つが、コンテキストの決定でした。単語というものは、それがどう使われるかによって非常に異なる意味を持つ場合があります。たとえば、「bank」という英単語は「銀行の預金残高」と「河川の堤防」というまったく異なる2つの熟語で使われるので、2つの異なる埋め込みが与えられる必要があります。
2013年から2018年にかけて、コンテキストの中にある他の単語を考慮しながらさまざまなモデルアーキテクチャーを使うことによって、埋め込みの質を高めようとする各種の論文が発表されました。この時期に最も影響力のあった論文は、Word2Vec (2013)、 Glove (2014)、Elmo (2018)で、単語の意味をコンテキストの中で捉えるためにさまざまな技法を試みています。これらの論文の基礎となっている技法は学ぶ価値の高いものですが、ChatGPTを理解しようというこの記事の目的とは異なるので扱いません。それでも、コンテキストの理解という考え方そのものは、ChatGPTの理解において非常に重要です。
機械学習
言語間のテキスト翻訳という課題は、さまざまなニューラルネットワークの進化を応用するための肥沃な土壌となりました。翻訳の鍵となる考え方は、完全な1つの文章をベクトル化し、その単語のすべての意味を捉えるという文章単位の埋め込みです。これにより、このベクトルを別のネットワークに移し、異なる言語のテキストに翻訳することが可能になります。ここには、文章を埋め込みにエンコードするエンコーダーネットワークと、それをデコードするデコーダーネットワークとがあるわけです。このような複合ネットワークなら、人間が翻訳したテキストがある2言語について、利用可能なあらゆるトレーニングデータで学習させることができます。
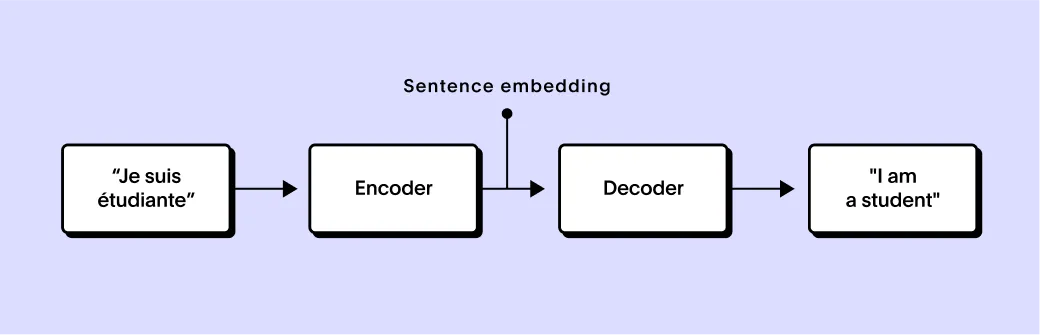
ニューラルネットワークを利用する初期の試みは、従来の技法に比べて有望であったことはもちろんですが、その後の多くのイノベーションの土台を作ったという意義も大きいと言えるでしょう。
ChatGPTはどのようにして人間の会話を理解するか
ここまで、単語や文章を高次元空間に埋め込むことが、多くのNLPタスクに役立っていることを見てきました。また、単語や文書をそれが発生するコンテキストの中で解釈することが非常に重要であり、また難しくもあることを確認しました。次の記事では、RNN構築から、ChatGPTを可能にした主要なイノベーションであるトランスフォーマーアーキテクチャーまで、さまざまなSeq2Seqモデルを見ていきます。

次の記事
トランスフォーマーアーキテクチャー:ChatGPTを支えるエンジン――RNNに始まりトランスフォーマーに至るSeq2Seqモデルを簡単に学びます 。


