




前の記事では、ChatGPTの基盤である計算言語モデルの歴史を要約して説明しましたが、さまざまなニューラルネットワークの接続方法、またその背後にある数値計算については説明をしませんでした。しかし、ここでChatGPTを支えるTransformerアーキテクチャーを取り上げるにあたり、わかりやすくするために詳細を少々説明しなければなりません。まず、いくつかの基本的な定義から説明してから、次のトピックの説明に移ります。
1. フィードフォワードネットワーク
2. RNN:順次データを処理できる最も簡素なニューラルネットワーク
3. LSTM:バニラRNNと比較して短期記憶をより長く保持できる特殊なRNN
4. Transformer(トランスフォーマー):ChatGPTおよび他のLLM(大規模言語モデル)を可能にするニューラルネットワークアーキテクチャー
機械学習
入力ベクトルXを取得しベクトルYを出力する関数Fについて考えます。
F(X) = Y
通常、計算ではほとんどの場合、関数Fおよび入力Xが指定され、Yを計算することになります。たとえば、FはF(X) = 3X + 2などの1次関数で、値X = 5が指定された場合、Y = 3*5 + 2 =17と計算することになります。
機械学習ではこのパラダイムを逆転させ、入力と出力の例から関数を計算します。たとえば、入力のペア(x=0, y=2)、(x=1, y=5)、(x=2, y=8)などから、Fが3X + 2であると推測できます。
ただし、ほとんどの場合、XとYの関係はこのように単純ではありません。Fをおおざっぱに概算するしかできません。たとえば、一連の点が与えられた場合に、それらの点に近い直線を当てはめることができます。これは多くの場合、線形回帰と呼ばれます。1次元では、線形回帰はF(X) = aX + bと記述でき、一連の点からaとbに最適な値を見つける必要があります。この場合、aとbは1次関数のプログラム可能なパラメーターです。
2次関数F(X) = aX2 + bX + c.を当てはめることもできます。ここではパラメーターが3つあり、関数がデータに近似するようにこれらのパラメーターを調整する必要があります。2つのパラメーターaおよびbがある指数曲線F(X) = aXbを当てはめることもできます。選択対象の関数の種類が多数存在する場合があります。さらにその種類ごとに独自の一連のパラメーターがあり、それらのパラメーターからデータに最適なものを選択できます。
通常、機械学習は、適切な種類の関数を選択してから、その種類の関数について学習データに最適なパラメーター値を見つけるプロセスです。
ニューラルネットワークとパラメーター
人工ニューラルネットワーク(ANN)は、脳の生体神経細胞を模した、パラメーター化された数学関数の一種です。平均して、脳内の1つの神経細胞は約1万個の他の神経細胞に接続されています。神経細胞は電気的刺激を介して情報を伝達します。神経細胞間の接続の強度により、神経細胞間で伝達される刺激の強さが決まります。物事を覚えたり忘れたりすると、これらの接続の強度が変化します。ある神経細胞に到達したすべての刺激の強さの合計がしきい値を超えると、その神経細胞が活動電位を発射し、電気的刺激を下流の神経細胞に送ります。
同様に、ANNでは人工神経細胞同士が接続され、2つの神経細胞間の接続の強さは学習プロセス時に設定されるプログラム可能なパラメーターです。多くの場合、神経細胞は多層化され、整理されます。最初の層は入力層と呼ばれ、最後の層は出力層と呼ばれます。各層は、作成者によって選択されたネットワークのアーキテクチャーによって決定される特定の方法で接続されます。大まかにいうと、ネットワーク内のプログラム可能な接続の数が多いほど、学習または記憶できる物事の数が増えます。また、プログラム可能なパラメーターや接続の数が多ければ、学習を有意義にするために必要な学習データが増え、ネットワークの学習や使用に必要な計算が増加します。
フィードフォワードネットワーク
最初はフィードフォワードネットワークと呼ばれるものから始まりました。このモデルでは、一連のニューラルネットワーク層が積み重ねられ、ある層の出力が次の層の入力となります。最初の層の入力を提供し、すべての計算を完了すると、ニューラルネットワークの出力が得られます。通常、各層は重みWのマトリックスで構成されます。このマトリックスを入力ベクトルに乗算することで、出力ベクトルが得られます。そこから、非線形関数を出力ベクトルの各値に適用できます。
このような種類のネットワークは、入力があると出力を計算でき、次の入力が提供されたときには何も記憶していない純粋な関数に相当します。たとえば、8x8の画像のすべてのピクセル値を入力として取得し、数字の画像の場合は1を出力し、それ以外の場合は0を出力するフィードフォワードネットワークをトレーニングできます。
このネットワークは固定サイズの入力を処理して固定サイズの出力を生成するのに適していますが、可変サイズのシーケンス(任意の長さの一連の単語など)を処理して可変サイズの出力(単語の翻訳を表す別の一連の単語)を生成する場合には適していません。
リカレントニューラルネットワーク(RNN)
「リカレント」とは、連続して、または間隔をあけて繰り返し発生することを意味します。リカレントニューラルネットワーク(RNN)では、時系列データや任意の長さの一連の単語を処理する際に同じ計算が繰り返し行われます。
APIが1秒間に呼び出される回数が与えられる非常にシンプルな問題を考えてみます。この呼び出し回数が1秒間に千回を超えると、アラートを出す必要があります。ただし、データにノイズが多いため、超過状態が一定期間持続しない場合はアラートを出さないようにします。そこで、1秒間のAPI呼び出し回数の指数平均を取得することにして、この指数平均が千を超過した場合にアラートを出します。xtが時間tにおけるAPI呼び出し回数を示し、htが減衰0.9での指数平均を示し、ytがアラートを出すかどうかを示すものとします。この場合、ytの計算は次のように記述できます。
h0 = 0
hi = 0.9 hi - 1 + 0.1 xi
yi = 1 if hi > 1000 else 0
計算の2行目と3行目は、時間ステップiごとに繰り返し発生します。これは、可変長シーケンスを処理して別の可変長シーケンスを出力する方法の例です。では、この概念を任意のベクトルおよび任意の関数に一般化してみましょう。
hi = F1(hi - 1, xi)
yi = F2(hi - 1, xi)
前のバージョンとこのバージョンの等式の唯一の違いは、特定の減衰が指定された指数平均の具体的な関数ではなく、任意の関数F1およびF2を使用している点です。RNNでは、F1およびF2はフィードフォワードネットワークであり、トレーニングデータに基づいてトレーニングされます。
単語の埋め込みのシーケンスを読み取ってその翻訳を出力するようにRNNをトレーニングできます。また、過去の気象データを入力として取得し、翌日の天気を予測するRNNもトレーニングできます。以前はしばらく、入力または出力にシーケンスが関係する場合は常に、RNNが選択されるアーキテクチャーだったことがありました。
RNNとフィードフォワードネットワークの違いは、フィードバックの要素にあります。ステップiで計算された出力hiは、ステップi + 1のネットワークにフィードバックされます。このフィードバックメカニズムにより、ネットワークは過去の一部の情報を記憶できます。また、一方でこのフィードバックメカニズムは、これらのネットワークのトレーニングを難しくもします。特に、いくつか前の時間ステップの内容をネットワークで記憶する必要があるタスクの場合にはそれが顕著です。
詳細については、こちらの有益な資料をご覧ください。
長・短期記憶(LSTM)ネットワーク
LSTMは特殊な種類のリカレントネットワークであり、最近の過去の短期記憶を基本的なRNNより長く保持するように設計されています。
上記と同様、APIが1秒間に呼び出される回数を取得する問題を考えてみましょう。ただし今回は、連続する5秒間にAPI呼び出しが行われなかった場合にアラートを出します。これは一種の機能停止を意味している可能性があります。この問題は指数平均では解決できません。これを行う方法の1つは、最新の5回の値のスライディングウィンドウを保持し、そのウィンドウの合計がゼロの場合にアラートを出すことです。数式は次のようになります。
Window0 = {}
Windowi = Windowi -1.erase( xi - 5).insert(xi)
yi = 1 if sum(Windowi) = 0 else 0
ここからLSTMにジャンプするのは、前よりも少々省略しすぎですが、同じ概念が適用されます。フィードフォワードニューラルネットワークを使用して、内部状態(Window)に格納される内容を取得する関数と内部状態で忘れる内容を取得する関数が計算される場合、LSTMの概念を利用できます。
これが基本的なRNNより有益である大きな理由は、複数の先行ステップからの入力について記憶できることが多いことです。短期記憶がより長く保持されるのです。RNNとLSTMの双方に関するこちらの有益な資料をご覧ください。
Attention
Attention(注意)も、最先端のモデルの動作を大幅に進歩させた非常に重要な概念です。フランス語の文「je suis étudiant」を「I am a student」(私は学生です)に翻訳するとします。単語「je」は「I」(私)にマップされ、単語「étudiant」は「student」(学生)にマップされます。「suis」は「am」と「a」にマップされているようなものです。したがって、対応する単語を生成する際に注意を要する単語を確認する場合、以下のようなマトリックスが非常に役立ちます。

この問題がどのように複雑になるのかを理解するために、下の画像をご覧ください。
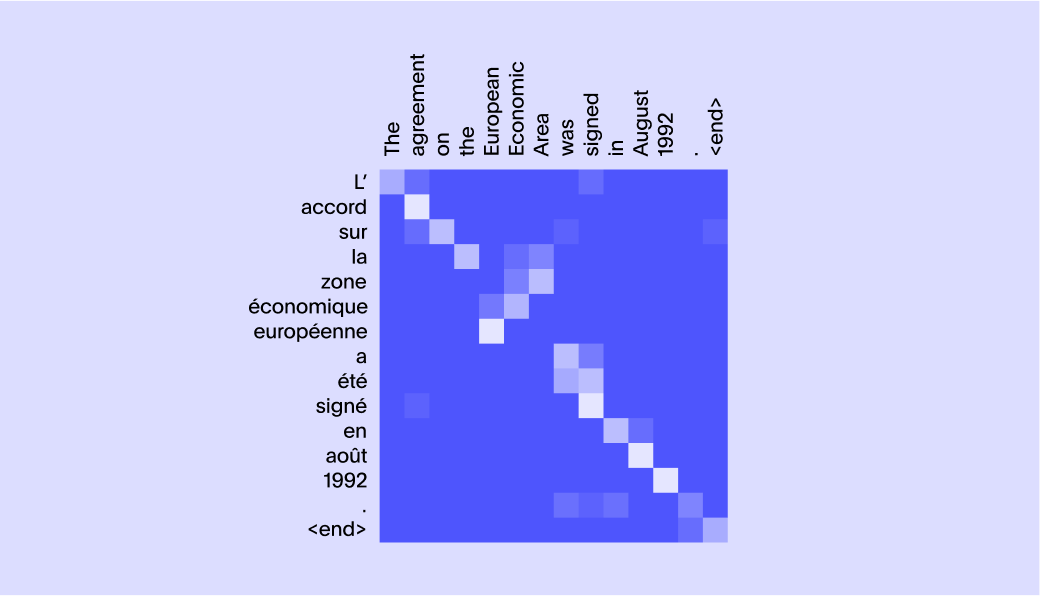
一部の単語は複数の単語の情報を必要とし、確実に1対1のマッピングではないことがわかります。
興味深いことに、単語を若干変更すると、Attentionマトリックスも変更されます。たとえば、文「The lamp could not be packed into the suitcase because it was too large」(ランプをスーツケースに入れることができませんでした。それが大きすぎたためです)では、「it」(それ)は「lamp」(ランプ)を指します。しかし、文「The lamp could not be packed into the suitcase because it was too small」(ランプをスーツケースに入れることができませんでした。それが小さすぎたためです)では、単語「it」(それ)は「suitcase」(スーツケース)を指します。したがって、これらのAttentionマトリックスを取得するには、データから学習するしかありません。これは、画期的な論文『Neural Machine Translation by Jointly Learning to Align and Translate』でまさに論じられている内容です。
ここで1つ注目すべきことは、RNNとLSTMを話題にしている場合は、これらのネットワークを介して最終的なベクトルを生成することができる任意の長さのシーケンスについて論じているということです。しかし、この手法は2つの理由から破棄されました。理由の1つ目は、入力と出力の長さにある程度の上限を設けなければ、Attentionマトリックスを計算できないことです。2つ目は、勾配消失問題があります。これの説明は若干難しくなります。
最新のニューラルネットワークのほとんどは、誤差(トレーニングラベルで出力と呼ばれるものと現在のネットワークで予測されているものの差)を伝播させることで学習します。これは、特定のノードから出力ノードへのパス内のすべてのノードの入力について、すべての出力の偏微分を乗算するということです。パスが長くなるにつれ、この偏微分の積が大きくなりすぎる、または小さくなりすぎる可能性が高くなります。大きすぎるとトレーニングプロセスが不安定になり、小さすぎるとトレーニングが十分に進まずに良好な結果が得られなくなります。いずれも好ましくありません。
RNNとLSTMでは、遠く離れている単語間の関係を学習するのが非常に困難でした。そのため、エンコーダーからデコーダーにAttentionプロセスを介してすべての中間隠れ状態を渡すアーキテクチャーが考案されました。この場合でも、ネットワークを固定長のシーケンスに制限する必要がありました。
Transformerアーキテクチャーとは
2017年、Googleの研究者がTransformerと呼ばれる新しいニューラルネットアーキテクチャーを発表しました。Transformerは、この4年間、この分野の飛躍的な進歩の大半の基盤となっています。論文のタイトルは『Attention is all you need』(必要なのはAttentionだけである)でした。このアーキテクチャーの中心的な概念が、RNNで利用されているフィードバックループではなく、AttentionとSelf-attentionを利用することであるためです。
Transformerアーキテクチャーの設計は、何が行われているのか、作者がなぜそれを選択したのかを理解することが非常に困難であるため、他のアーキテクチャーと比較して独自性が少々高くなっています。これを理解するには、多くの詳細を把握する必要があります。しかし、選択の背後には確固とした洞察と論拠があります。次のセクションでは、このアーキテクチャーの背後にある重要な洞察について説明します。
Transformerアーキテクチャーの能力
Transformerアーキテクチャーが得意としていることが2つあります。1つ目は、文脈に当てはめる方法の学習が得意です。たとえば、文を処理する際に、語句の意味は使用されている文脈によってまったく違うものになることがあります。多くの場合、この文脈に当てはめる方法は、文法の関数であるだけでなく、現実世界に存在する関係の関数でもあります。このアーキテクチャーは、そのSelf-attentionメカニズムによりデータドリブンの方法で文脈を応用する方法を学習することが得意です。2つ目は、このアーキテクチャーは、トレーニングおよび推論時における計算の大規模並列化に適していることです。これにより、例をトレーニングする際のスループットが大幅に高速化し、特定の時間スケールでより多くのトレーニングデータでより大きなネットワークをトレーニングできます。元の論文で使用されている2億1,300万個のパラメーターを備えた最大のTransformerモデルは、8個のGPUを使用して3.5日でトレーニングが行われています。
TransformerモデルのSelf-attentionとは
Self-attentionとは、テキスト本文で文脈を構成する他の単語に注意することで、ネットワークで単語を文脈に当てはめるメカニズムです。Self-attentionの概念は、前述のAttentionの概念と似ていますが、上記の翻訳で単語を対応させたのとは異なり、文内の単語が文脈への当てはめに使用されます。
次の2つの文について考えます。
ご覧のとおり、最初の文では車、2つ目の文では動物について述べています。このように理解できるのはなぜでしょうか。これは、車にはドアがあり、動物がほえることを人間が知っているからです。これを知るには、現実世界の概念や物体およびその相互関係に関する多くのことを認識するしかありません。
この問題を解決するために、Transformerモデルではニューラルネットワークを使用して、単語ごとにクエリーと呼ばれるベクトルとキーと呼ばれるベクトルを生成します。ある単語のクエリーが別の単語のキーに一致すると、2つ目の単語は最初の単語と関連する文脈を持っているということになります。2つ目の単語から最初の単語に適切な文脈を提供するために、値と呼ばれる3つ目のベクトルが生成されます。このベクトルと最初の単語を組み合わせることで、取得される最初の単語の意味が文脈に沿ったものになります。
ここでは多くの複雑な数式を簡素化していますが、留意すべき重要なことの1つに、このような仕組みが機能するには、使用されるすべての関数が緩やかな傾き(勾配)を持つように数式を設計して、学習アルゴリズムで各例から最適な重みを見つけ出せるようにする必要があります。Transformerの優秀性は主に、学習プロセスが収束し、その収束が迅速に行われるようにメカニズムが設計されている点にあります。
また、Transformerの作成者がAttentionのためのベクトルのサイズを小さくしながら、複数の並列Attentionメカニズムが並列実行されるようにしたことも独創的でした。これにより、ニューラルネットワークでさまざまな種類の文脈を並行して収集して複数のショットを取得できます。また、Self-attention層を複数回繰り返すことで、ネットワークではより大きな複数の語句の文脈を結合できます。たとえば、「It was a knockoff of the 1984 ad from Apple」(それはAppleの1984年の広告の模倣だった)という文を考えます。まず、単語「Apple」の曖昧性を解消する必要があります。広告および1984年という文脈から、これは間違いなく会社であり、果物ではありません。次に、「1984」の意味を理解するための文脈があります。さらに、「it」(それ)が指すものを文脈に当てはめます。ここでは推測になりますが、Self-attention層の複数化は、一連の推論を連続的に行う必要がある場合に非常に役立つと思われます。
Self-attentionに加え、Transformerでは位置エンコーディングの概念も導入されました。これにより、ネットワーク構造が文内の単語の相対位置の影響をうけなくなります。位置情報は後から三角関数の形式で入力として追加されます。これは非常に興味深い選択であり、ネットワークの有効性を高めることができると考えられます。
この記事ではエンコーダー層、デコーダー層、および他のAttentionメカニズムの詳細はあえて取り上げませんが、詳細に興味がある場合は、『The Illustrated Transformer』を読むことを強くお勧めします。
BERT(Bidirectional Encoder Representations from Transformers、Transformerからの双方向エンコーダー表現)
当初、Transformerアーキテクチャーは機械学習コミュニティー以外ではあまり注目されませんでした。しかし、その後少ししてから、Googleの研究者がNLPタスク向けの新しいTransformerモデルをトレーニングし、複数の領域で記録を塗り替えました。
モデルのトレーニングは次の2つの目的を達成するために行われました。
1. テキスト本文から欠けている単語を推測する
2. 2つの文を与えられたときに、1つの文書内の連続する2文であるのか、学習データ全体からランダムに選択された2文なのかを推測する。
また、文のベクトル埋め込みを出力するようにネットワークを設計し、そのネットワークの上にもう1つの小規模なネットワークを使用することで、感情分析、文の類似度、質問への回答などの多種多様な言語タスクに使用できるようにしました。
衆目を集めたのは、BERTが多くの言語タスクで優れた成果を出し、最先端の記録を塗り替えたことでした。この時点で、単に優れた研究上の概念ではなくなっていました。ThoughtSpotも含め、業界内のさまざまな製品チームが動向を注視し、この分野の進歩を活用する方法を模索しはじめました。
最大のBERTモデルには3億4,500万個のパラメーターがありました。推定コスト7,000ドルで4日間かけて、Google が開発した専用学習ハードウェアであるTPU(Tensor Processing Unit、テンソルプロセッシングユニット)を64個使用してトレーニングされました。一方で、新しいイノベーションにかかるハードウェアへの投資がますます増えると人々を心配させました。またもう一方では、モデルが大規模であるほど、スマートになり、多くの知識を収集できるということが明確に示されました。このため、2つの若干異なるグループができました。1つはNLPに対して大規模なTransformerネットワークをトレーニングして、どれだけスマートになるのかを確認したいと考えるグループで、もう1つはBERTの優れた点をいくつか保持しながら小規模なネットワークをトレーニングしたいと考えるグループでした。
GPTとBERTの比較
GPT(Generative Pretrained Transformer、生成事前学習済みTransformer)は、言語モデリングタスク向けにOpenAIでトレーニングされたトランスファーモデルの一種です。最初のGPTモデルはBERTモデルより前に登場しました。BERTは卓越したトレーニング目的に従うものでしたが、OpenAIは次の単語を予測するモデルのトレーニングの方向に進みました(言語モデリング)。最初のGPTモデルには1億1,700万個のパラメーターがあり、多くのタスクで最先端の記録を大幅に塗り替えました。ただし、15億個のパラメーターを使用するGPT-2が登場するまで、衆目を集めることはありませんでした。
GPTの背後にある当初の構想は、大規模なテキスト本文を使用して言語モデリングタスクでネットワークの事前トレーニングを行ってから、各種言語タスク用にネットワークを調整するというものでした。このようにすることで、人間が生成したラベル付きデータを使用することなくモデルに対して教師なしのトレーニングを行い、特定のタスクでは小規模なラベル付きデータを使用して教師ありトレーニングのメリットも活かせます。このため、事前トレーニングという用語が含まれています。さらに驚くべきことは、言語モデリングのタスク自体が極めて強力なツールになったことでした。モデルに話しかけて、タスクの実行を依頼するだけで、ある程度賢い回答を返して人々を驚かせるのです。
入力テキストから次の単語を予測するようにネットワークをトレーニングしただけです。しかし、提供したテキストによっては、このモデルはわずか数年前には考えられなかったような知性の兆候を示したのでした。この結果、入力テキストをプロンプトと呼びはじめました。次の記事では、プロンプトテキストおよびGTP-3の回答の例をいくつか確認し、大規模言語モデルの新たな特性を示します。
実際、GPTだけでなく、複数の他のLLMで、モデルが特定のしきい値サイズ(500億~1,000億個のパラメーター)を超えると、質問への回答能力の面で非常に興味深い特性を示しはじめます。次の記事では、さらにLLMの新たな特性およびChatGPTの学習方法について解説し、LLMの新たな性質を活用します。





